# Website: https://quanteda.io/ library (quanteda)
Warning: package 'quanteda' was built under R version 4.5.3
Package version: 4.3.1
Unicode version: 15.1
ICU version: 74.1
Parallel computing: 12 of 12 threads used.
See https://quanteda.io for tutorials and examples.
library (quanteda.textmodels)
Warning: package 'quanteda.textmodels' was built under R version 4.5.3
library (quanteda.textplots)
Warning: package 'quanteda.textplots' was built under R version 4.5.3
Warning: package 'readr' was built under R version 4.5.3
Warning: package 'ggplot2' was built under R version 4.5.3
# Twitter data about President Biden and Xi summit in Novemeber 2021 # Do some background search/study on the event # <- read_csv ("https://raw.githubusercontent.com/datageneration/datamethods/master/textanalytics/summit_11162021.csv" )
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (50): screen_name, text, source, reply_to_screen_name, hashtags, symbol...
dbl (26): user_id, status_id, display_text_width, reply_to_status_id, reply...
lgl (10): is_quote, is_retweet, quote_count, reply_count, ext_media_type, q...
dttm (4): created_at, quoted_created_at, retweet_created_at, account_create...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
View (summit)= summit$ text= tokens (sum_twt)<- dfm (toks)class (toks)# Latent Semantic Analysis ## (https://quanteda.io/reference/textmodel_lsa.html) <- textmodel_lsa (sumtwtdfm, nd= 4 , margin = c ("both" , "documents" , "features" ))summary (sum_lsa)
Length Class Mode
sk 4 -none- numeric
docs 58080 -none- numeric
features 63972 -none- numeric
matrix_low_rank 232218360 -none- numeric
data 232218360 dgCMatrix S4
[,1] [,2] [,3] [,4]
text1 8.678102e-03 9.529008e-03 -3.178574e-03 1.380732e-02
text2 8.676818e-06 -8.806186e-06 -5.989637e-06 1.677631e-05
text3 2.922127e-03 6.778967e-03 1.131673e-03 -3.176902e-03
text4 1.046624e-02 8.884054e-04 -4.282723e-03 4.960680e-03
text5 3.251208e-03 8.005843e-03 2.208204e-04 -4.656367e-03
text6 3.251208e-03 8.005843e-03 2.208204e-04 -4.656367e-03
<- tokens (sum_twt, remove_punct = TRUE ) %>% dfm ()head (tweet_dfm)
Document-feature matrix of: 6 documents, 15,927 features (99.89% sparse) and 0 docvars.
features
docs breaking news us president biden amp communist china leader xi
text1 1 1 1 1 1 1 1 2 1 1
text2 0 0 0 0 0 0 0 0 0 0
text3 0 0 0 0 1 0 0 0 0 1
text4 0 0 0 1 1 0 0 0 0 1
text5 0 0 0 0 1 0 0 0 0 1
text6 0 0 0 0 1 0 0 0 0 1
[ reached max_nfeat ... 15,917 more features ]
<- dfm_select (tweet_dfm, pattern = "#*" )<- names (topfeatures (tag_dfm, 100 ))head (toptag, 20 )
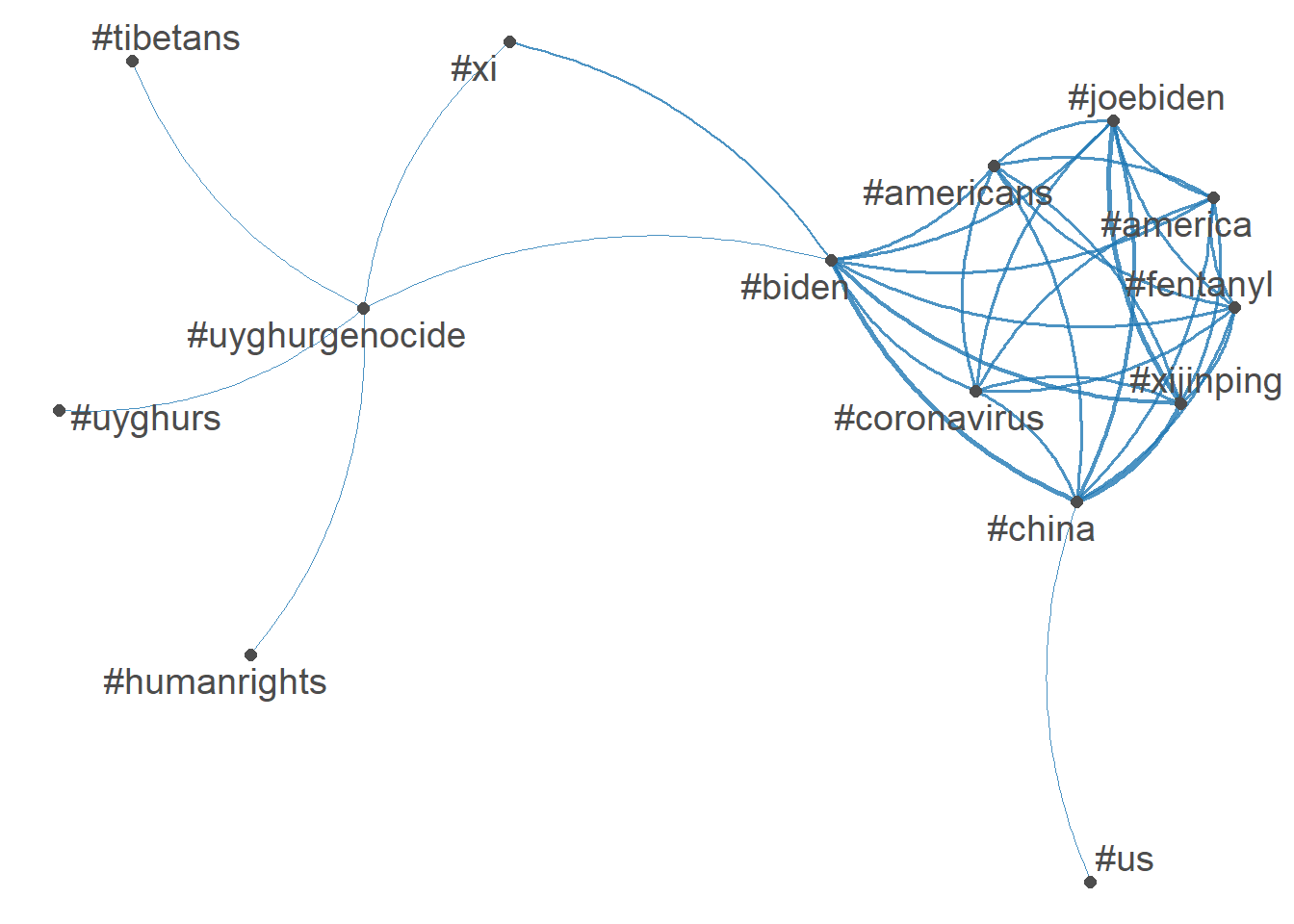
[1] "#china" "#biden" "#xijinping" "#joebiden"
[5] "#america" "#americans" "#coronavirus" "#fentanyl"
[9] "#xi" "#us" "#uyghurgenocide" "#taiwan"
[13] "#foxnews" "#usa" "#breaking" "#news"
[17] "#ccp" "#humanrights" "#uyghurs" "#tibetans"
library ("quanteda.textplots" )<- fcm (tag_dfm)head (tag_fcm)
Feature co-occurrence matrix of: 6 by 665 features.
features
features #breaking #breakingnews #biden #china #usa #pray4america
#breaking 0 4 5 5 5 0
#breakingnews 0 0 4 5 4 0
#biden 0 0 0 443 49 0
#china 0 0 0 8 76 0
#usa 0 0 0 0 6 0
#pray4america 0 0 0 0 0 0
features
features #joebiden #xijinping #america #americans
#breaking 0 0 0 0
#breakingnews 0 0 0 0
#biden 299 370 302 295
#china 339 434 308 295
#usa 12 15 0 0
#pray4america 0 0 0 0
[ reached max_nfeat ... 655 more features ]
<- fcm_select (tag_fcm, pattern = toptag)textplot_network (topgat_fcm, min_freq = 100 , edge_alpha = 0.8 , edge_size = 1 )<- dfm_select (tweet_dfm, pattern = "@*" )<- names (topfeatures (user_dfm, 100 ))head (topuser, 50 )
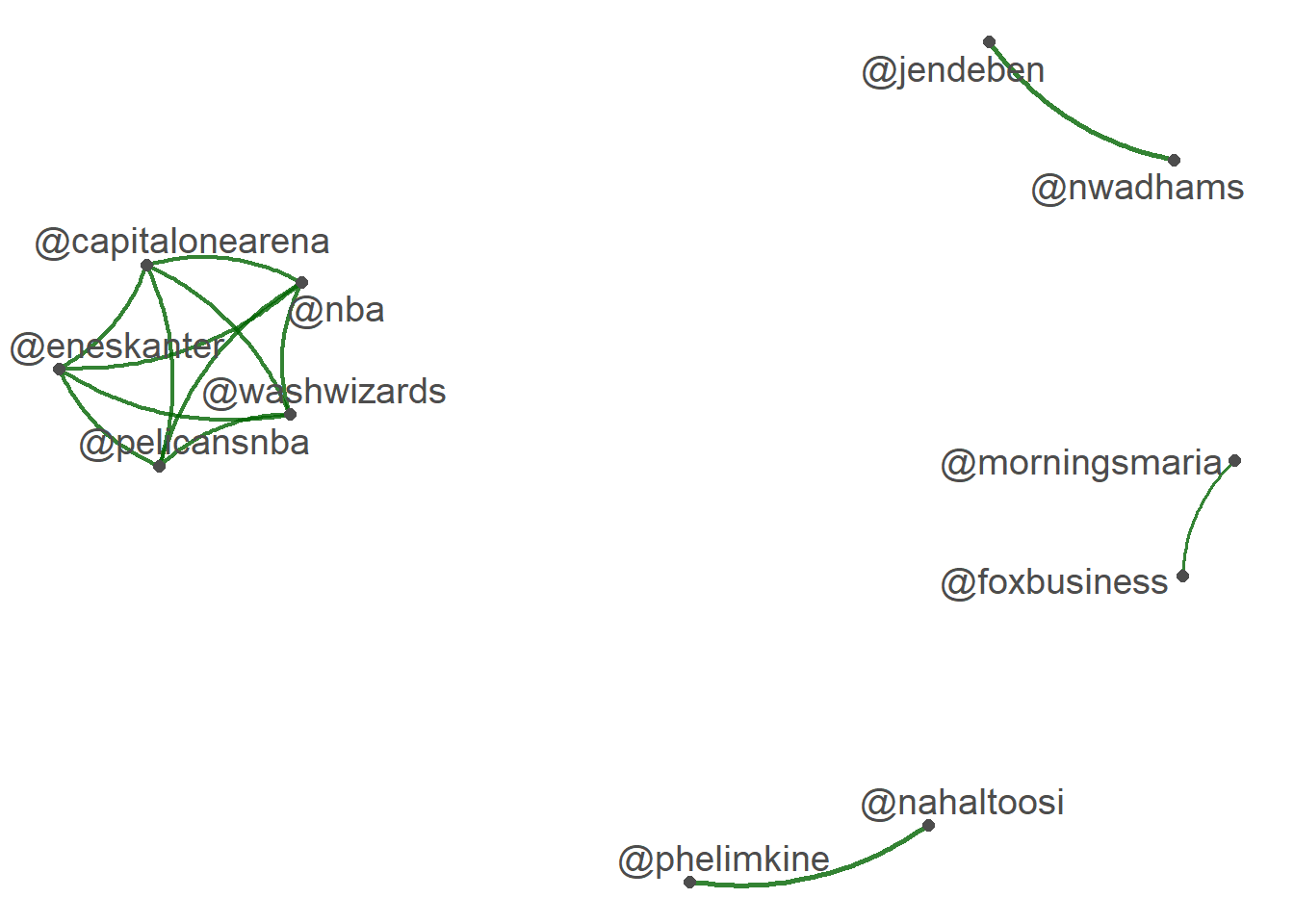
[1] "@potus" "@politico" "@joebiden" "@jendeben"
[5] "@eneskanter" "@nwadhams" "@phelimkine" "@nahaltoosi"
[9] "@nba" "@washwizards" "@pelicansnba" "@capitalonearena"
[13] "@kevinliptakcnn" "@foxbusiness" "@morningsmaria" "@scmpnews"
[17] "@petermartin_pcm" "@nytimes" "@uyghur_american" "@kaylatausche"
[21] "@presssec" "@bpolitics" "@nypost" "@anderscorr"
[25] "@whnsc" "@foxnews" "@jewherilham" "@whitehouse"
[29] "@onlyyoontv" "@thehillopinion" "@dannyrrussel" "@learyreports"
[33] "@glubold" "@betamoroney" "@enilev" "@evasmartai"
[37] "@globaltaiwan" "@david_culver" "@ethancpaul" "@davidfickling"
[41] "@paulhaenle" "@fredfleitz" "@forbes" "@asiasociety"
[45] "@nathaniel_sher" "@ak_mack" "@googlenews" "@knottmatthew"
[49] "@voachinese" "@wsj"
<- fcm (user_dfm)head (user_fcm, 50 )
Feature co-occurrence matrix of: 50 by 711 features.
features
features @youtube @bfmtv @cnn @lauhaim @barackobama @joebiden
@youtube 0 0 0 0 0 0
@bfmtv 0 0 1 1 1 1
@cnn 0 0 0 1 1 1
@lauhaim 0 0 0 0 1 1
@barackobama 0 0 0 0 0 1
@joebiden 0 0 0 0 0 3
@kamalaharris 0 0 0 0 0 0
@hillaryclinton 0 0 0 0 0 0
@billclinton 0 0 0 0 0 0
@cbsnews 0 0 0 0 0 0
features
features @kamalaharris @hillaryclinton @billclinton @cbsnews
@youtube 0 0 0 0
@bfmtv 1 1 1 1
@cnn 1 1 1 1
@lauhaim 1 1 1 1
@barackobama 1 1 1 1
@joebiden 1 1 1 1
@kamalaharris 0 1 1 1
@hillaryclinton 0 0 1 1
@billclinton 0 0 0 1
@cbsnews 0 0 0 0
[ reached max_nfeat ... 40 more features, reached max_nfeat ... 701 more features ]
<- fcm_select (user_fcm, pattern = topuser)textplot_network (user_fcm, min_freq = 50 , edge_color = "darkgreen" , edge_alpha = 0.8 , edge_size = 1 )